搜索引擎springboot集成(elasticSearch)
各位小伙伴们,今天是今年的最后一天,这是我今年的最后一篇博客,在这里祝大家新年快乐!本次讲的是近几年比较流行的search搜索引擎,本文写的比较粗略,希望大家看了会有所收获,如若写错,请在评论区指出,我感激不尽!
1 搜索引擎springboot集成(elasticSearch)
1.1 为什么要使用ElasticSearch
实际项目中,我们建立一个网站或应用程序,并要添加搜索功能,令我们受打击的是:搜索工作是很难的。我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON/XML通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并在需要扩容时方便地扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。
虽然全文搜索领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
1.2 ElasticSearch(简称ES)
ES即为了解决原生Lucene使用的不足,优化Lucene的调用方式,并实现了高可用的分布式集群的搜索方案,其第一个版本于2010年2月出现在GitHub上并迅速成为最受欢迎的项目之一。
首先,ES的索引库管理支持依然是基于Apache Lucene™的开源搜索引擎。ES也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。Lucene直接通过java API调用,而ES把这些API调用过程进行了的封装为简单RESTful请求,让我们调用起来更加简单.
不过,ES的核心不在于Lucene,其特点更多的体现为:分布式的实时文件存储,每个字段都被索引并可被搜索,分布式的实时分析搜索引擎,可以扩展到上百台服务器,处理PB级结构化或非结构化数据,高度集成化的服务,你的应用可以通过简单的 RESTful API、各种语言的客户端甚至命令行与之交互。上手Elasticsearch非常容易。它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它拥有开瓶即饮的效果(安装即可使用),只需很少的学习既可在生产环境中使用。
Lucene和ES联系,区别:项目中为啥使用ES而不用Lucene.
联系:ElasticSearch封装了Lucene,让使用变得更简单,在高可用上面做得更好。
区别:ElasticSearch除了拥有Lucene所有优点以外,还拥有自己优点.
可用性:支持集群没有单点故障
扩展性:支持集群扩展
一般lucene在中小型项目中使用(但是也能使用es),而ES在大型项目中使用.因为ES支持在集群环境使用,并且自身也支持集群.
2 ES安装及使用说明
官网地址=>https://www.elastic.co/cn/elasticsearch
自行搜索
3 ES数据管理
3.1 什么是ES中的文档
ES是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index,创建索引)每个文档的内容使之可以被搜索。在ES中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
ES使用Javascript对象符号(JavaScript Object Notation),也就是JSON,作为文档序列化格式。JSON现在已经被大多语言所支持,而且已经成为NoSQL领域的标准格式。
ES存储的一个员工文档的格式示例:
{
“email”: “wb@bbcc.com”,
“name”: “文兵”,
“info”: {
“addr”: “四川省成都市”,
“age”: 30,
“interests”: [ “樱桃”, “粉嫩” ]
},
“join_date”: “2014-06-01”
}
尽管原始的 employee对象很复杂,但它的结构和对象的含义已经被完整的体现在JSON中了,在ES中将对象转化为JSON并做索引要比在表结构中做相同的事情简单的多。
一个文档不只有数据。它还包含元数据(metadata)—关于文档的信息。三个必须的元数据节点是:
| 节点 | 说明 |
|---|---|
| _index | 索引库,文档存储的地方 |
| _type | 文档类型(6.x之后取消掉了这个属性) |
| _id | 文档的唯一标识 |
_index:索引库,类似于关系型数据库里的“数据库”—它是我们存储和索引关联数据的地方。
_type:类型,类似于关系型数据库中表.在应用中,我们使用对象表示一些“事物”,例如一个用户、一篇博客、一个评论,或者一封邮件。可以是大写或小写,不能包含下划线或逗号。我们将使用 employee 做为类型名。
_id: 与 _index 和 _type 组合时,就可以在ELasticsearch中唯一标识一个文档。当创建一个文档,你可以自定义 _id ,也可以让Elasticsearch帮你自动生成。
另外还包括:_uid 文档唯一标识(_type#_id)
_source:文档原始数据
_all:所有字段的连接字符串
3.2 文档的增删改
我们以员工对象为例,我们首先要做的是存储员工数据,每个文档代表一个员工。在ES中存储数据的行为就叫做索引(indexing),文档归属于一种类型(type),而这些类型存在于索引(index)中,我们可以简单的对比传统数据库和ES的对应关系:
关系数据库(MYSQL) -> 数据库DB-> 表TABLE-> 行ROW-> 列Column
Elasticsearch -> 索引库Indices -> 类型Types -> 文档Documents -> 字段Fields
ES集群可以包含多个索引(indices)(数据库),每一个索引库中可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
创建索引文档
使用自己的ID创建
PUT {index}/{type}/{id}{ "field": "value", ...}使用内置ID创建
POST {index}/{type}{ "field": "value", ...}获取指定ID的文档
GET itsource/employee/123更新文档
PUT {index}/{type}/{id}{ "field": "value", ...}跟创建语法一样,但是会改变版本号
删除文档
DELETE {index}/{type}/{id}注意:尽管文档不存在,但_version依旧增加了。这是内部记录的一部分,它确保在多节点间不同操作可以有正确的顺序
put和post是差不多的,都可以用来修改和添加,唯一区别就是,在添加时put需要手动给id而post不需要赋id,系统自动给个随机id
3.3 文档的简单查询(searchAPI)
GET /_search
GET /woniu47/_search
GET /woniu47,woniu48/_search
GET /woniu*/_search
URLsearch:
通过ID获取
GET /woniu47/_doc/1
只返回文档内容,不要元数据:
GET /woniu47/_doc/1/_source
查询字符串搜索:
返回文档的部分字段:
GET /woniu47/_doc/1?_source=name,age
查询年龄为25岁的学员
GET /woniu47/_search?q=age:25
组合查询:
组合查询:
+表示并且,多个条件做且运算====>MUST
空格表示或,多个条件做或运算====>SHOULD
-表示非,多个条件做非运算====>MUST_NOT
+name:john +tweet:mary
+name:(mary john) +date:>2014-09-10 +(aggregations geo)
age[20 TO 30]
查询年龄在25到28 (两边都包括)或则姓名为wangwu的学员
GET /woniu47/_search?q=age:>=25 +age<=28 name:wangwu
GET /woniu47/_search?q=age[25 TO 28] name:wangwu
中括号可以换成大括号,中括号有=大括号没有
分页:
查询20岁以上的学员,显示3条
GET /woniu47/_search?q=age:>=20&size=3
查询20岁以上的学员,每页显示3条,显示第2页
GET /woniu47/_search?q=age:>=20&size=3&from=3
查询参数说明:
| Name | Description |
|---|---|
| q | 标识查询字符串 |
| df | 在查询中,没有定义字段前缀的情况下默认字段的前缀 |
| analyzer | 在分析查询字符串时,分析器的名字 |
| default_operator | 被用到的默认操作,有AND和OR两种,默认是OR |
| explain | 对于每一个命中,对怎样得到命中得分的计算给出一个解释 |
| _source | 将其设置为false,查询就会放弃检索_source字段。也可以通过设置检索部分文档 |
| fields | 标识查询字符串 |
| sort | 排序执行,可以fieldName、fieldName:asc |
| track_scores | 当排序的时候,将其设置为true,可以返回相关度得分 |
| from | 分页查询起始点,默认0 |
| size | 查询数量,默认10 |
| search_type | 搜索操作执行的类型 |
4 索引与分词
4.1 什么是倒排索引
倒排索引是先将文档进行分词处理,标记每个词都出现在哪些文档里面,这样就可以快速查询某个词所出现的文档位置。与之对应的是“正排索引”,例如我们看一本书的目录,从前往后查找目录,就是正排索引。
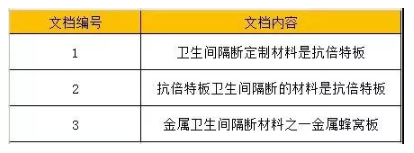
我们先来看3组文档,我们将文档编号分别列为1、2、3。
https://img-blog.csdnimg.cn/img_convert/23778d72d45fcf1d7532e55f1baba182.png
{kind=link}
这3个文档里,核心词是“卫生间隔断”,如果你在搜索引擎上,直接搜索卫生间隔断,抛开文章内容,单看标题,哪个排第一?没错,就是文档1会出现在第一位,为什么?
因为倒排索引里,会通过单词词典,统计一个单词在文档里出现的位置。我们将上述文档里出现的词,都赋予一个ID。
这是一个最简单的倒排索引示意图:
4.2 什么是分词
分词是指将文本转换成一系列单词的过程,也可以叫文本分析,在es里面称为Analysis,如下图所示:
分词器是ES中专门处理分词的组件,英文为Analyzer,它的组成如下:
- Character Filters
针对原始文本进行处理,比如去除html特殊标记
- Tokenizer
将原始文本按照一定规则切分为单词
- Token Filters
针对tokenizer处理的单词进行再加工,比如转小写、删除或新增等处理
4.3 Analyze API
ES提供了一个测试分词的api接口,方便验证分词效果,endpoint是_analyze
直接指定analyzer进行测试
POST _analyze{ "analyzer": "standard", "text": "hello world"}直接指定索引中的字段进行测试
POST woniu47/_analyze{ "field": "name", "text": "hello java"}ES自带分词器如下:
| Name | Description |
|---|---|
| standard | 默认分词器,按词切分,支持多语言,小写处理 |
| simple | 按照非字母切分,小写处理 |
| whitespace | 按照空格切分 |
| stop | 相比simple 多了stop word处理(语气2组词等修饰性的词语,比如the、an、的、这等等) |
| keyword | 不分词,直接将输入作为一个单词输出 |
| pattern | 通过正则表达式自定义分割符,默认是\W+, 即非字词的符号作为分隔符 |
4.4 中文分词器
中文分词器是将一个汉字序列切分成一个一个单独的词。在英语中,单词之间是以空格作为自然分界符,汉语中词没有一个形式上的分界符。上下文不同,分词结果迥异,比如交叉歧义问题,比如下面两种分词都合理:
- 乒乓球拍/卖/完了
- 乒乓球/拍卖/完了
常用分词系统
1.IK
实现中英文单词的切分,支持ik_smart、ik_maxword等模式,
可自定义词库,支持热更新分词词典
2.jieba
python中最流行的分词系统,支持分词和词性标注
支持繁体分词、自定义词典、并行分词等
https://github.com/sing1ee/elasticsearch-jieba-plugin
IK的使用
1.安装
- git clone https://github.com/medcl/elasticsearch-analysis-ik
- cd elasticsearch-analysis-ik
- mvn clean
- mvn compile
- mvn package
- 拷贝和解压release下的文件: #{project_path}/elasticsearch-analysis-ik/target/releases/elasticsearch-analysis-ik-*.zip 到你的 elasticsearch 插件目录, 如: plugins/ik 重启elasticsearch
2.测试
POST _analyze{ "analyzer": "ik_smart", "text": "中华人民共和国国歌"}POST _analyze{ "analyzer": "ik_max_word", "text": "中华人民共和国国歌"}3.ik_smart与ik_max_word的区别
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合,适合 Term Query;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合 Phrase 查询
注意: 在config文件夹下面有很多扩展词的配置
5 Mapping(文档映射)
ES的文档映射(mapping)机制用于进行字段类型确认(字段是什么类型,什么分词器),将每个字段匹配为一种确定的数据类型。类似于数据库的表结构定义,主要作用如下:
定义Index下的字段名(Field Name)
定义字段的类型,比如数值型、字符串型、布尔型等
定义倒排索引相关配置,比如是否索引、记录position等
查看某个Index的Mapping
GET woniu47/_mapping5.1 自定义Mapping
创建一个Index的映射
PUT woniu48{ "mappings": { "properties": { "name": { "type": "keyword" }, "age": { "type": "integer" }, "desc": { "type": "text", "analyzer": "ik_smart" } } }}Mapping中的字段类型一旦设定后,禁止直接修改,因为Lucene实现的倒排索引生成后不允许修改
通过dynamic参数来控制字段的新增
true(默认)允许自动新增字段
false 不允许自动新增字段,但是文档可以正常写入,但无法对字段进行查询等操作
strict 文档不能写入,报错
PUT woniu48{ "mappings": { "dynamic": "false", "properties": { "name": { "type": "keyword" }, "age": { "type": "integer" }, "desc": { "type": "text", "analyzer": "ik_smart" } } }}copy_to
- 将该字段的值复制到目标字段,实现类似_all的作用
不会出现在_source中,只用来搜索
PUT woniu48{ "mappings": { "dynamic": "false", "properties": { "name": { "type": "keyword", "copy_to": "full_name" }, "age": { "type": "integer" }, "desc": { "type": "text", "analyzer": "ik_smart", "copy_to": "full_name" }, "full_name": { "type": "text" } } }}index
- 控制当前字段是否索引,默认为true,即记录索引,false不记录,即不可搜索
PUT woniu48{ "mappings": { "dynamic": "false", "properties": { "name": { "type": "keyword", "index": false }, "age": { "type": "integer" }, "desc": { "type": "text", "analyzer": "ik_smart", "copy_to": "full_name" } } }}name字段不能够用来搜索
null_value
- 当字段遇到null值时的处理策略,默认为null,即空值,此时ES会忽略该值,不会创建索引。可以通过设定该值得一个空值的替换值来对空值进行索引,可以用替换值进行对空值的搜索
PUT woniu48{ "mappings": { "properties": { "name": { "type": "keyword" }, "age": { "type": "integer" }, "desc": { "type": "text", "analyzer": "ik_smart" }, "sex": { "type": "keyword", "null_value": "null" } } }}使用null替换了空值,下面添加一个空值
PUT woniu48/_doc/1{ "name": "zs", "age": 23, "desc": "中国人很好", "sex": null}可以使用替换的null值来进行空值搜索
GET woniu48/_search{ "query": { "match": { "sex": "null" } }}ignore_above
- 该属性是keyword类型的一个属性,用来规定字段值长度,超出这个长度的字段将不会被索引,但是会存储。
PUT woniu48{ "mappings": { "properties": { "name": { "type": "text", "fields": { "pinyin": { "type": "keyword", "ignore_above": 5 } } }, "age": { "type": "integer" } } }}多字段特性 multi-fields
- 允许对同一个字段采用不同的配置,比如分词,常见的例子如一个字段我需要通过索引分词查询也需要能够通过精装匹配查询
PUT woniu48{ "mappings": { "properties": { "name": { "type": "text", "fields": { "pinyin": { "type": "keyword" } } }, "age": { "type": "integer" } } }}index_options
- 用来控制倒排索引记录的内容
docs: 只记录doc id
freqs : 记录doc id和term frequencies
positions: 记录doc id、term frequencies和term position
offsets: 记录doc id、term frequencies、term position和character offsets
text类型默认配置为positions,其他默认为docs,记录内容越多,占用空间越大
5.2 数据类型
核心数据类型
字符串型: text、keyword
数值型: long、integer、short、byte、double、float、half_float、scaled_float
日期类型: date
布尔类型: boolean
二进制类型: binary
范围类型: integer_range、float_range、long_range、double_range、date_range
复杂数据类型
数组类型: array
对象类型: object
嵌套类型: nested object
地理位置数据类型
geo_point
geo_shape
专用类型
ip: 记录IP地址
completion: 实现自动补全
token_count: 记录分词数
murmur3: 记录字符串hash值
5.3 Dynamic Mapping(自动映射)
ES在没有配置Mapping的情况下新增文档,ES可以自动识别文档字段类型,并动态生成字段和类型的映射关系。
ES是依靠JSON文档的字段类型来实现自动识别字段类型,支持的类型如下:
JSON类型ES类型
null忽略
booleanboolean
浮点类型float
整数long
objectobject
array由第一个非null值得类型决定
string匹配为日期格式则设为date类型(默认开启);
匹配为数字的话设为float或long类型(默认关闭)设为text类型,并附带keyword子字段
6 DSL查询
由ES提供丰富且灵活的查询语言叫做DSL查询(Query DSL)。将查询语句通过http request body发送到ES,主要包含如下参数:
query符合Query DSL语法的查询语句
from、size
timeout
sort
。。。
例如:
GET woniu48/_search
{
"query": {
"term": {
"name": "lisi"
}
}
}
基于JSON定义的查询语言,主要包含如下两种类型
字段类查询
如term、match、range等,只针对某一个字段进行查询
复合查询
如bool查询等,包含一个或多个字段类查询或则复合查询语句
6.1 字段类查询
Match Query流程
字段类查询主要包括以下两类:
全文匹配针对text类型的字段进行全文检索,会对查询语句先进行分词处理,如match、match_phrase等query类型单词匹配不会对查询语句做分词处理,直接匹配字段的倒排索引,如term、terms、range等query类型全文匹配(Match Query)GET woniu48/_search{ "query": { "match": { "username": "alfred way" } }}**通过operator参数可以控制单词间的匹配关系,可选项为or或则and**GET woniu48/_search{ "query": { "match": { "desc": { "query": "非常漂亮", "operator": "and" } } }}上面查询如果分词器分词为“非常”、“漂亮”两个词,查询匹配结果就必须同时包含这两个词的文档单词匹配(Term Query)GET woniu48/_search{ "query": { "term": { "name": "lisi" } }}一次传入多个单词进行查询GET woniu48/_search{ "query": { "terms": { "name": [ "lisi", "wangmazi" ] } }}Range Query(范围查询)GET woniu48/_search{ "query": { "range": { "age": { "gte": 20, "lte": 23 } } }}6.2 复合查询
复合查询是指包含字段类查询或复合查询的类型,主要包括以下几类:
constant_score query
bool query *
dis_max query
function_score query
boosting query
Bool Query
布尔查询由一个或多个布尔子句组成,主要包含如下4个:
NameDescription
filter只过滤符合条件的文档,不计算相关性得分
must文档必须复合must中的所有条件,会影响相关性得分
must_not文档必须不符合must_not中的所有条件
should文档可以符合should中的条件,会影响相关性得分
Filter Filter查询只过滤符合条件的文档,不会进行相关性算分
ES针对Filter会有智能缓存,因此其执行效率很高
做简单匹配查询且不考虑算分时,推荐使用filter替代query等
GET woniu48/_search{ "query": { "bool": { "filter": [ { "term": { "name": "admin" } }, { "range": { "age": { "gte": 25 } } } ] } }}- must
GET woniu48/_search{ "query": { "bool": { "must": [ { "match": { "desc": "漂亮的人" } }, { "range": { "age": { "gte": 22 } } } ] } }}- must_not
查询描述里面经过分词有“漂亮”一词以及不带“非常”一词的结果
GET woniu48/_search{ "query": { "bool": { "must": [ { "match": { "desc": "漂亮的人" } } ], "must_not": [ { "match": { "desc": "非常好" } } ] } }}- should
只包含should时,文档必须至少满足一个条件(minimun_should_match可以控制满足条件的个数或则百分比)
例如:下面至少满足一个条件
GET woniu48/_search{ "query": { "bool": { "should": [ { "match": { "desc": "漂亮的人" } }, { "range": { "age": { "lte": 20 } } } ] } }}例如:下面需要满足两个条件
GET woniu48/_search{ "query": { "bool": { "should": [ { "match": { "desc": "漂亮的人" } }, { "range": { "age": { "lte": 20 } } } ], "minimum_should_match": 2 } }}同时包含should和must时,文档不必满足should中的条件,但是如果满足条件,会增加相关性得分
该查询只会以must匹配来搜索
GET woniu48/_search{ "query": { "bool": { "should": [ { "range": { "age": { "lte": 19 } } } ], "must": [ { "match": { "desc": "漂亮的人" } } ] } }}综合实例
查询年龄大于20并且包含“漂亮的人”描述或则年龄小于18的学员,分页显示第2页,每页显示2条,且按照年龄由低到高排序
GET woniu48/_search{ "query": { "bool": { "should": [ { "bool": { "must": [ { "match": { "desc": "漂亮的人" } }, { "range": { "age": { "gte": 20 } } } ] } }, { "range": { "age": { "lte": 18 } } } ] } }, "from": 2, "size": 2, "sort": [ { "age": { "order": "desc" } } ]}7 SpringBoot集成
可以通过Spring Data Elasticsearch来进行操作,boot对其进行了集成:
导包
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>配置连接
spring: elasticsearch: rest: uris: - http://localhost:9200注入模板对象
@Autowired
ElasticsearchOperations operations;
7.1 对象映射
ES的文档对应于Java的对象,可以通过Spring-Data-Es提供的注解来进行关联:
@Data@Document(indexName = "woniu48")public class Student {@Id@Field(type = FieldType.Integer,name = "id")private Integer id;@Field(type = FieldType.Keyword,name="name")private String name;@Field(type = FieldType.Integer,name="age")private Integer age;@Field(type = FieldType.Text,analyzer = "ik_max_word",name = "desc")private String desc;}@Document: 在类级别应用,以指示该类是映射到ES的哪一个Index。最重要的属性是:
indexName: 用于存储此实体的索引的名称
@Id: 用来标识ID
@Field: 在字段级别应用并定义字段的属性:
name: 字段名称
type: 字段类型
analyzer: 分词器
7.2 操作
保存(新增与更新)对象:
Student stu = new Student();stu.setId(3333);stu.setName("张三丰");stu.setDesc("此人涨得不好看");stu.setAge(100);operations.save(stu);删除对象:
//第一个参数是idoperations.delete("3333", Student.class);查询对象:
查询有三种主要方式:通过CriteriaQuery条件来查询,可以简单组合条件,不能分词,适用于非常简单的查询//查询年龄在20-25之间或则名称是"admin"的学员Criteria c = new Criteria("age").between(20, 25).or("name").is("admin");CriteriaQuery cq = new CriteriaQuery(c);SearchHits<Student> shs = operations.search(cq, Student.class);System.out.println(shs.getTotalHits());shs.getSearchHits().forEach(student -> {System.out.println(student.getContent().getName()+":"+student.getContent().getAge());});通过StringQuery来查询,直接在java这边构建查询json字符串,不推荐使用通过NativeSearchQuery来构建复杂查询,包括bool查询等等,推荐使用/*查询匹配非常漂亮的人或则年龄在90以上的*///构建NativeSearchQuery建造器NativeSearchQueryBuilder nsqb = new NativeSearchQueryBuilder();//构造Bool查询条件BoolQueryBuilder bqb = new BoolQueryBuilder();//通过该Bool查询器构建should查询器List<QueryBuilder> should = bqb.should();//向should里面添加两个查询条件should.add(new MatchQueryBuilder("desc", "非常漂亮的人"));should.add(new RangeQueryBuilder("age").gt(90));//注册bool查询条件nsqb.withQuery(bqb);//注册分页(第一页,显示3条)nsqb.withPageable(PageRequest.of(0, 3));//注册排序(age降序)nsqb.withSort(SortBuilders.fieldSort("age").order(SortOrder.DESC));//构建NativeSearchQueryNativeSearchQuery nsq = nsqb.build();//执行查询方法SearchHits<Student> shs = operations.search(nsq, Student.class);System.out.println(shs.getTotalHits());shs.getSearchHits().forEach(x -> {Student stu = x.getContent();System.out.println(stu.getName()+":"+stu.getDesc()+":"+stu.getAge());});查询结果高亮显示
//创建高亮显示器HighlightBuilder hb = new HighlightBuilder();//设置高亮字段hb.field("desc");//设置为false,匹配字段都会高亮显示hb.requireFieldMatch(false);//设置如何高亮显示hb.preTags("<span style=\"color:red\">");hb.postTags("</span>");//设置高亮显示范围以字符为单位hb.fragmentSize(800);//设置高亮显示的开始位置hb.numOfFragments(0);NativeSearchQueryBuilder nsqb = new NativeSearchQueryBuilder();//注册高亮显示器nsqb.withHighlightBuilder(hb);nsqb.withQuery(new MatchQueryBuilder("desc", "非常漂亮"));NativeSearchQuery nsq = nsqb.build();SearchHits<Student> shs = operations.search(nsq, Student.class);shs.getSearchHits().forEach(x -> {Student stu = x.getContent(); String desc = stu.getDesc(); //获取高亮显示字段List<String> hs = x.getHighlightField("desc"); if(hs != null && hs.size() > 0) desc = hs.get(0);System.out.println(stu.getName()+":"+desc);});