在这篇文章中,我将向您展示使用表的第5个参数(可选的比较器函数)所能做的神奇事情。PowerBI和Power查询中的组M-函数:表.组参数作为桌子,钥匙和其他东西一样,集合柱作为列表,可选的groupKind作为可空号,可选比较器作为可空函数如果您已经不熟悉第四个参数(GroupKind),我强烈建议您阅读ChrisWebb的文章,因为我们将在此知识的基础上再接再厉。对于GroupKind.local中的模式而言,另一个值得一提的方面是性能方面:对于大型数据集,它的运行速度要比默认设置快得多。因此,如果您确信您的数据将始终得到相应的排序,则可以大大加快分组操作。这意味着:默认情况下,您的数据必须正确排序。至少在我的测试中,一旦您按照明确的步骤对表进行排序,就会失去性能增益。您可以找到比较器函数的概述。这里.不区分大小写分组想象一下Chris的数据集中有一个转折,看起来是这样的:
表.组-修改后的源数据我们可能不会对这些结果感到满意:
具有大小写敏感性的群问题因为M在缺省情况下是区分大小写的,所以我们得到的组比我们想要的多。让我们试试比较。
很干净,不是吗?

(您也可以在其他函数中使用该比较器,请参见这里 用于文本和列表操作)这就是前几天我给黄彩光看的,他问我这个函数的第五个参数是什么(至少我理解了)。然后他派人我链接到他的一篇文章,这需要我很好的两个小时来消化和理解:我们也可以使用自定义函数在这里创建各种不同的分组行为。这是我最喜欢的两个:1.分析所有时间记录
2.分析让我们再调整一下数据集,并增加一些假期:
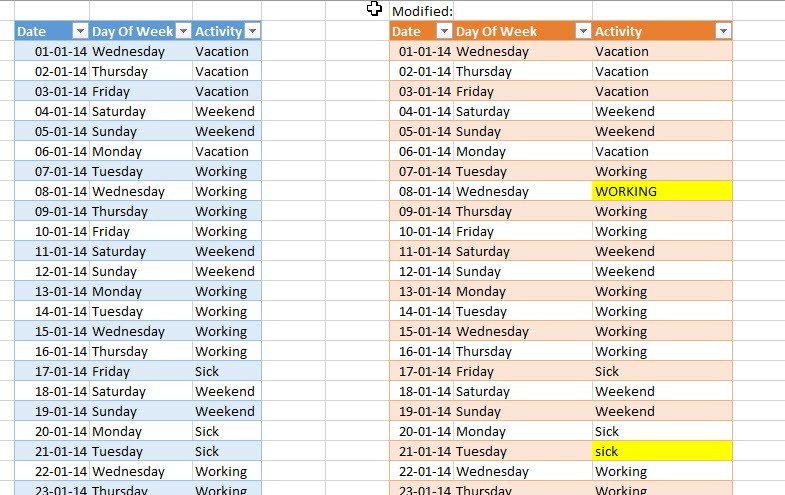
假期间事件分析假设我们想分析每个假期之间发生的一切:
休假之间事件的分组但这是怎么回事?我不太清楚,但我的猜测是:如果使用第5个参数,Table.Group-函数将向函数传递2个参数:对于GroupKind.Local,这是组-列-来自表/组的初始/第一行的记录和当前行的相应记录。只要比较函数返回0,当前行将被视为属于组:这是比较函数中的匹配。1.记录在案:Table.Group(#"Changed Type", {"TMAX"}, <Aggregated columns expressions>, 0, (x,y) => Number.From(x[TMAX]<y[TMAX]))我们检查当前记录的温度是否高于当前组的初始记录。如果为真,则结果为1,并将创建一个新的组。2.下列事件:Table.Group(FilteredRows, "Activity", <Aggregated columns expressions>, 0, (x,y) => Number.From(x=y))在这里,我们检查全部记录的相等性,只要它们不相等,0将被返回,它们将留在组中。当返回与组的第一个记录(“Vacation”)相同的值时,将创建一个新的组。我还没有找到如何在这个语法中包含比较。ProgramalIgnoreCase,但是如果您想使这个大小写不敏感,您可以像这样将参数转换为小写:…(x,y)=>Number.From(Text.下限(X)=Text.下限(Y))(如果键(第二个参数)是文本而不是列表(“活动”而不是{“活动”})。如果您检查示例文件中的查询“全面活动探索”,您会注意到将传递给全局组类型的第5个参数的参数是完全不同的:记录中的更多字段和不同的行顺序。您是否有其他的用例可以根据连续的顺序创建组,该顺序将项与每个组的第一项进行比较?请在评论中分享。下载的文件:表5元享受和保持牢骚满腹
分享如下:点击Twitter分享(打开新窗口)点击LinkedIn分享(打开新窗口)点击Facebook分享(打开新窗口)单击此邮件发送给朋友(打开新窗口)单击以打印(在新窗口中打开)就像这样: